Abstract
In the field of deep reinforcement learning, algorithms are often constrained by challenges such as sample efficiency, model uncertainty, and dynamic changes in the environment. We introduces a novel reinforcement learning method utilizing Bayesian dynamic ensembles to address model uncertainty, thereby enhancing robustness and adaptability in varying environments. Our approach centers on a probabilistic network ensemble model that refines environmental dynamics and reward function estimations, incorporating a dynamic weight updating mechanism via Bayesian principles and importance sampling for improved model inference stability. Through extensive experiments, we demonstrate superior performance and generalizability of our method, particularly in bipedal locomotion tasks, and explore its robustness through ablation studies examining model resilience against extended imagining lengths and external noise.
Method
Model-Based Policy Optimization
The Model-Based Policy Optimization (MBPO) algorithm proposes an innovative methodology for the effective utilization of environmental models. The principal concept underlying this approach is the implementation of short-horizon rollouts using the model, as opposed to conducting full trajectory simulations from the initial state. This strategy is encapsulated in the ‘branched rollout’ technique within MBPO. By generating new, short-term ‘branches’ on trajectories that have been previously sampled from the actual environment, the branched rollout method constrains the cumulative error inherent in the model, thus preserving the efficiency of the rollouts and enhancing the overall performance of the policy.

Bayesian Dynamic Ensemble
In MBPO, the stochasticity inherent in selecting a specific submodel from an ensemble during the imagination phase frequently results in diminished robustness across various tasks. This variability can undermine the reliability and performance consistency of the MBPO framework, particularly in complex environments where accurate prediction and decision-making are critical. To mitigate these challenges, we propose the implementation of a Bayesian dynamic ensemble approach, which takes inspiration from the Bayesian model averaging (BMA) technique.
So, during the imagination phase, we use a weighted average approach instead of randomly using the output of a submodel as the parameters of the Gaussian distribution, as done in the MBPO methods. Suppose we use the following notation to describe the reinforcement learning process:
where:
If we want to calculate the weights for each model, it is crucial to derive the conditional probability \( \color{purple}{p(\mathcal H_{t-1} = m \mid y_{0:t-1})} \) from \( \color{green}{p(\mathcal H_{t} = m \mid y_{0:t})} \). This procedure enables continuous refinement of the model parameters at each timestep \( t \) and involves the following principal steps:
- Exponential Smoothing with a Forgetting Factor: Begin by considering the transformation of the prior probability into a smoothed prior as dictated by the following equation, as detailed in 1: $$ \color{blue}{p(\mathcal H_{t} = m \mid y_{0:t-1})} \color{black}{=} \frac{\color{purple}{p(\mathcal H_{t-1} = m \mid y_{0:t-1})}^{\color{black}{\alpha}}}{\sum\limits_{j = 1}^{M} \color{purple}{p(\mathcal H_{t-1} = j \mid y_{0:t-1})}^{\color{black}{\alpha}}} $$ Here, \( \alpha \) represents a forgetting factor within the interval \( (0, 1) \) and serves as a hyperparameter to modulate the influence of historical data.
- Application of Bayes’ Rule: Update the model’s belief about the current state by applying Bayes’ rule to incorporate new evidence: $$ \color{green}{p(\mathcal H_{t} = m \mid y_{0:t})} \color{black}{=} \frac{\color{blue}{p(\mathcal H_{t} = m \mid y_{0:t-1})} \color{red}{p_m(y_{t} \mid y_{0:t-1})}}{\sum\limits_{j=1}^{M} \color{blue}{p(\mathcal H_{t} = j \mid y_{0:t-1})} \color{red}{p_j(y_{t}\mid y_{0:t-1})}} $$
- Computation of the Likelihood: The likelihood component \( \color{red}{p_m(y_{t} \mid y_{0:t-1})} \) is computed as follows, integrating over all possible states: $$ \color{red}{p_{m}(y_{t}\mid y_{0:t-1})} \color{black}= \int p_{m}(y_{t}\mid x_{t}) p(x_{t}\mid y_{0:t-1}) , dx_{t} $$ It can be estimated by importance sampling, as detailed in the subsequent section.
The above steps outline a structured approach to recursively updating the probabilistic beliefs about the system’s state by smoothly transitioning prior beliefs with new observational data, thus refining the model’s predictions over time.
Sequential Importance Sampling
We can estimate it using sequential importance sampling as follows: $$ \color{red}{p_{m}(y_{t}\mid y_{0:t-1})} \color{black} \approx \sum\limits_{i=1}^{N_{s}} w_{t-1}^{i}p_{m}(y_{t} \mid x_{t}^{i}) $$

Experiments
We have validated the effectiveness of our algorithm in classical control environment and the Mujoco environment. During the imagination phase, we employed different inference methods, namely MBPO and Simple Averaging. Our findings indicate that our approach generally outperforms the comparative methods.
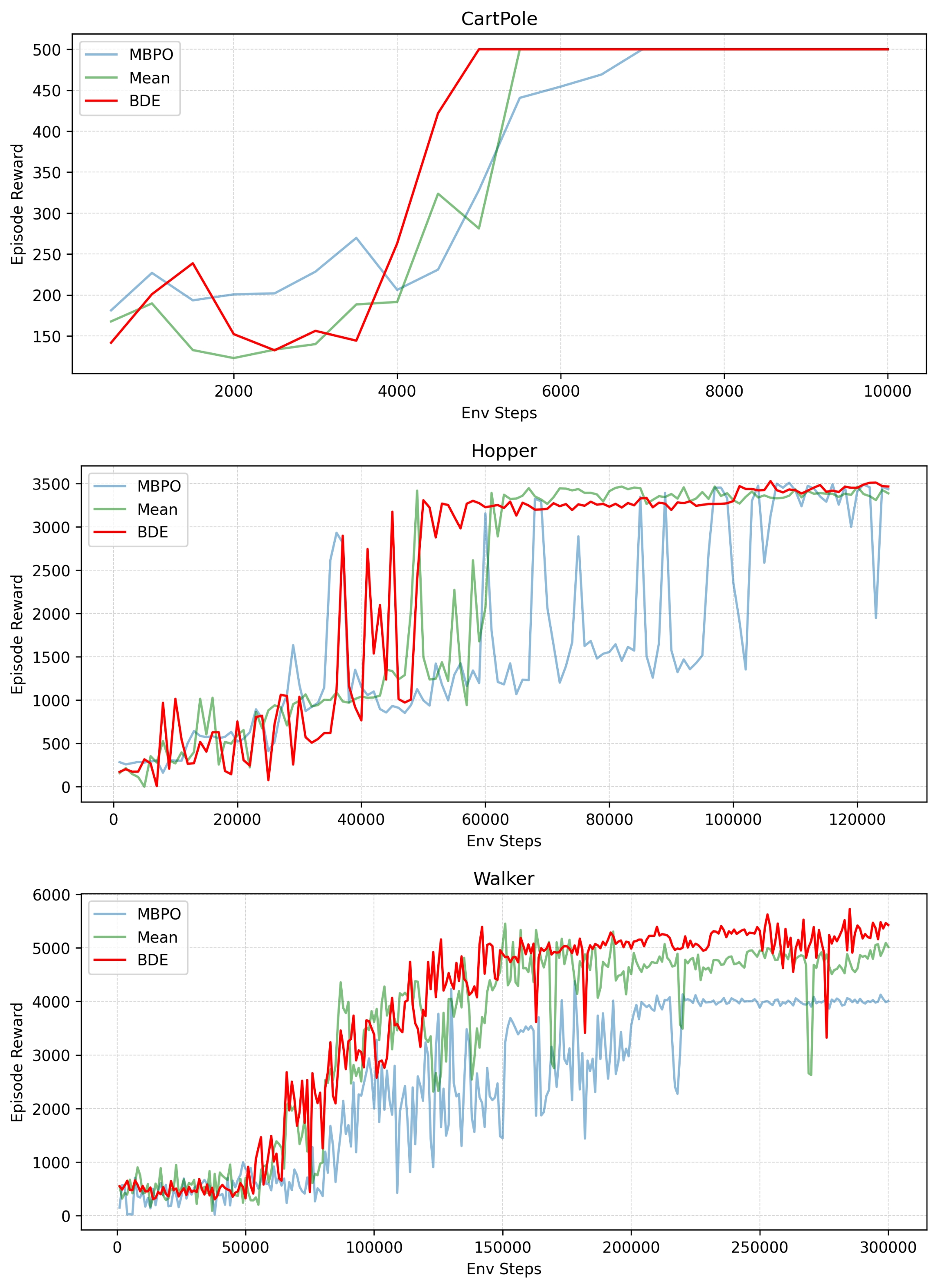
Ablaition Study
To be updated…